I am using aichat and a local LLM inside Ghostty to replace Warp. Why?
- Warp’s app icon is ugly, and Ghostty’s app icon is beautiful.
- I challenge myself to work with a local LLM instead of a free version of a paid LLM product. I have to connect the local LLM to Ghostty via aichat.
At the time of writing, the local LLM is qwen3-4b-2507 served by LM Studio. The model is the best among models of its size for me. I used Grok (x.ai) to install Ghostty, aichat (rustup + cargo), and LM Studio. I recommend model configs as below.
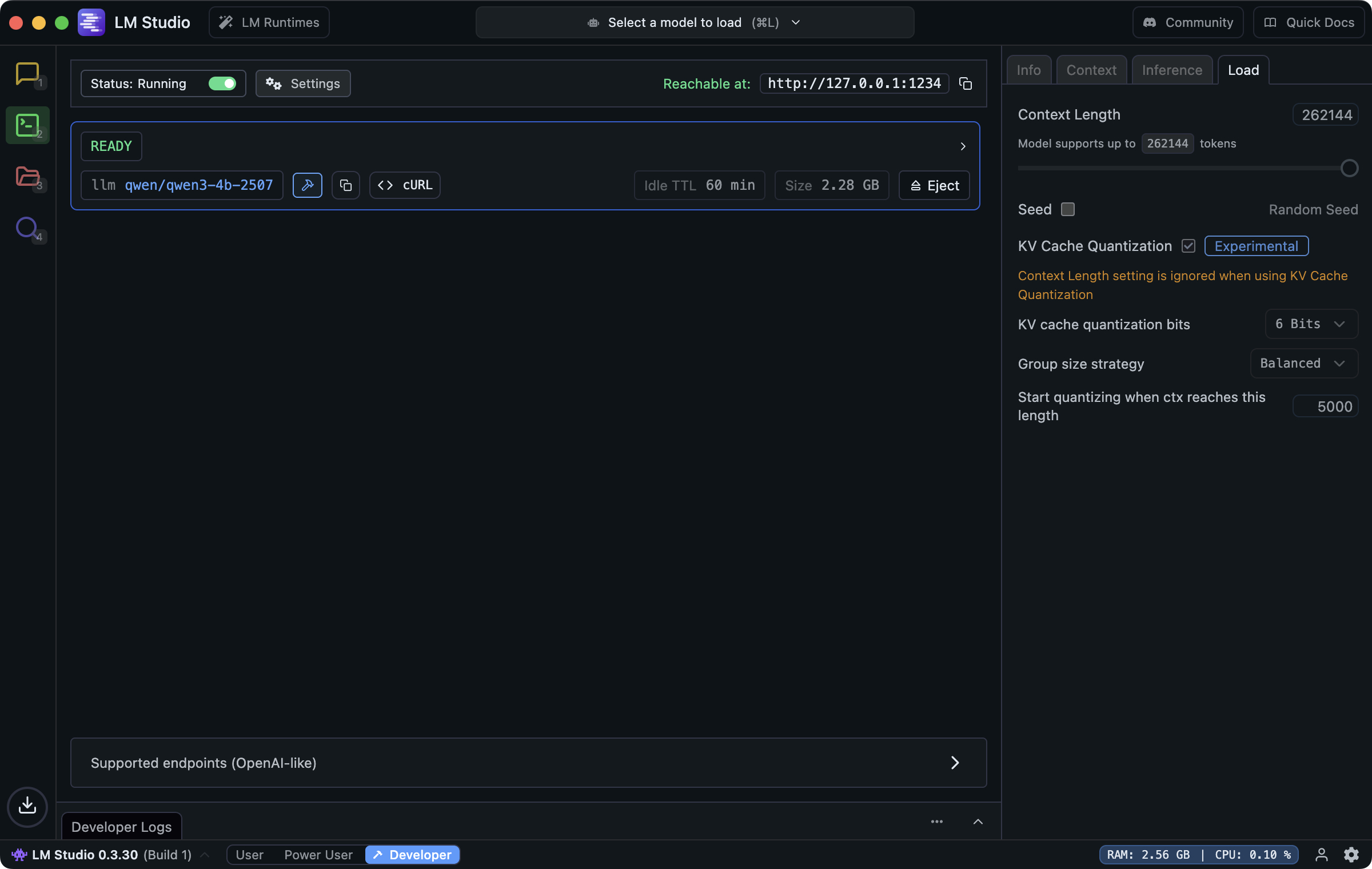
6 bits quantization is recommended by an Apple’s staff working on their AI.
Some data to help decide on what the right precision is for Qwen3 4B (Instruct 2507).
— Awni Hannun (@awnihannun) October 11, 2025
I ran the full MMLU Pro eval, plus some efficiency benchmarks with the model at every precision from 4-bit to bf16.
TLDR 6-bit is a very decent option at < 1% gap in quality to the full… pic.twitter.com/YQsOL9ZPw1